Text Externalization and Localizations¶
PolicyModels offers a text externalization/localization mechanism. This mechanism can be used when decision graph questions require long texts, or when there’s a need to present a model in more than one language. Another advantage of having the texts outside of the interview is that it allows text editing by domain experts who are not familiar with PolicyModel’s syntax.
During an interview, the system will use localized texts when available, and default to the texts in the policy model itself when no localized value is available. Thus, it is possible to only partially localize an interview – useful for those times when only a few questions are too long and need to be pulled out for editing.
Note
Localization data are used by the web-based interview. CliRunner uses the texts from the model.
All elements of a policy model can be localized, as detailed below. Localizations live in a special sub-directory in the model directory, called languages. Each localization has its own directory. The name of the directory of a given localization should reflect the language and dialect of the localization. This can be done using codes (such as ISO-639 and ISO-3166).
Formats¶
PolicyModel localizations make use of plan text, HTML, and – mostly – GitHub-flavored markdown. Markdown provides a good balance between rich features (such as formatting, hyperlinking and graphics) and simple syntax. Multiple visual markdown editors are available, including free, open source and web-based ones.
Localizing Model Elements¶
In this section, we look into how different parts of a model can be localized.
Tip
There’s no need to manually create the files listed here; they can be created automatically from CliRunner by executing the command \loc-create.
Tip
When a model is updated after a localization package has been created, this package can be updated to the new model by executing command \loc-update.
Model Metadata¶
The textual parts of the policy model description file are localized using an XML file named localized-model.xml. This file contains localizations for the title, sub-title, authors, and keywords.
Readme¶
The readme file should contain general, free-form text about the model. The system supports three formats for a readme file: HTML, markdown, and plain text. In case more than a single file is present, the file with the richer format will be displayed (e.g. given a text and a markdown file, the system will use the markdown one).
Policy Space¶
Policy space texts are stored in a file named space.md. It consists of a list of slot and value names, followed by their localized name, tooltip, and descriptive texts.
The format for slot localization is as follows (each bullet is a line in the file):
- Item start:
# typePath. The line starts with#, then has a full or non-ambiguous slot/value name, and that’s it. - Localized name of the slot/value.
- Short description (typically a single, short sentence). This description will appear in tool-tips.
- Separator line:
--- - Long explanation text, in markdown. This explanation may use multiple lines, and ends when the next description starts, or when the file ends.
Note
Policy space localizations support line comments (<-- I'm a comment)
Below is an example of a space.md file:
# DataRepoCompliance/FAIR
FAIR
Findable, Accessible, Interoperable, Reusable
---
Read more at [FAIR principles](https://www.dtls.nl/fair-data/fair-principles-explained/).
# DataRepoCompliance/FAIR/Accessible
Accessible
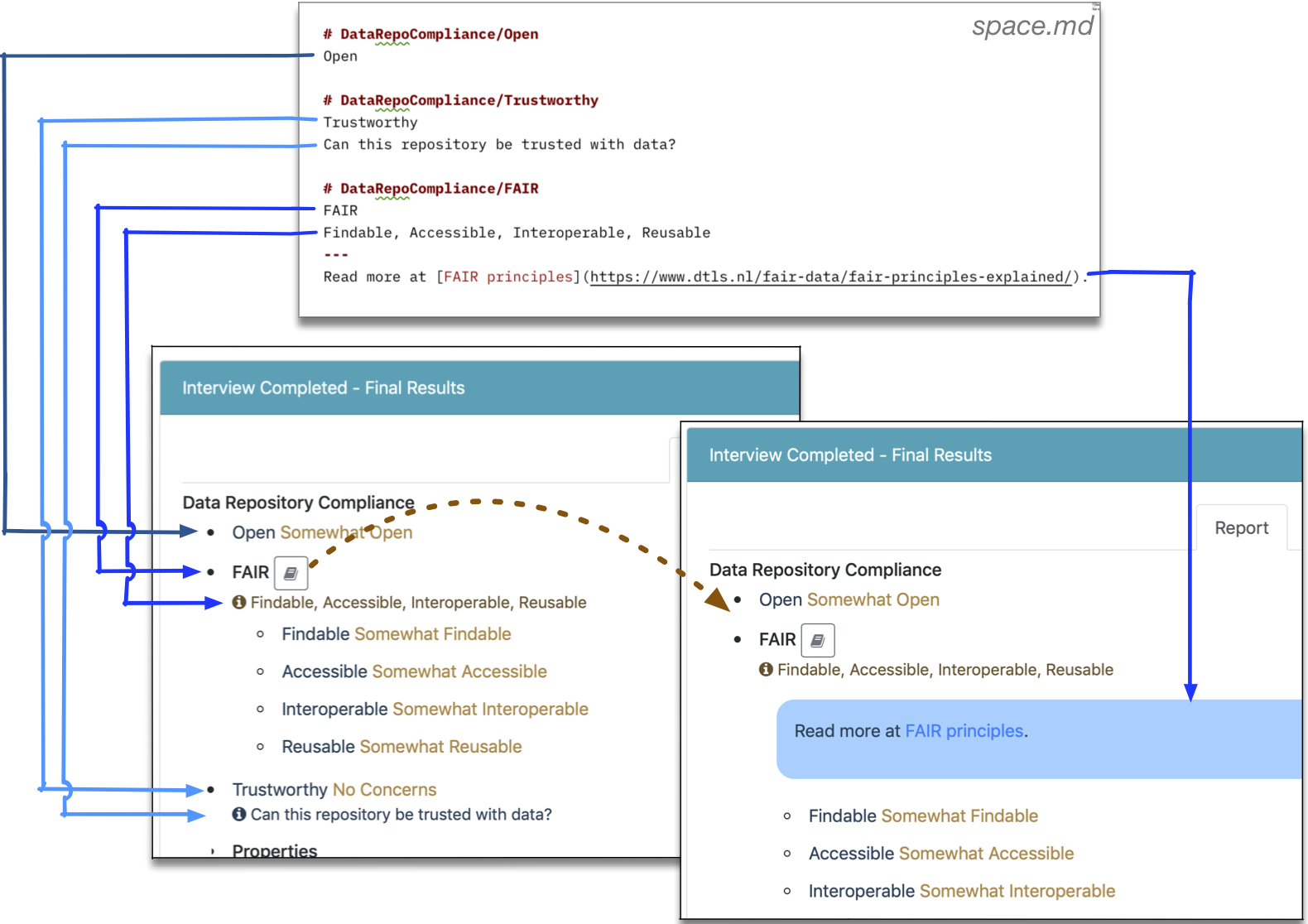
Policy space localization. All policy space entities (slots and values) are localized using the space.md file of the localization package. For each entity, translators can specify name, short explanation, and a long explanation. The long explanation supports links, tables, and rich styling.
Answers¶
The answers.txt file localizes the answer names. Each line contains the answer in the decision graph and its localized name, separated by a colon.
Line-comments (<--) are also supported, for convenience.
<-- common answers
yes: sí
no: no
maybe: tal vez <-- used when unsure
<-- Support for §17.a
biology: biología
sociology: sociología
other: otro
Sections¶
Section nodes can be localized using a sections.md file in the localization directory. This file uses the same format as the policy space localization file.
# [mainFile.dg]sInitialRouting
Initial Routing
This part of the interview gathers basic data.
---
The art of interviewee routing is as ancient as the art of interviews
itself, and some say even older [London,77](http://link/to/evidence).
Indeed, this is not a concept to be taken for granted, not is it a
matter which technical reference manuals should use for examples of
lengthy texts in markdown. However, ...
Decision Graph Elements¶
Decision graph elements that contain texts (ask, todo, and reject) can be localized by adding a file to the nodes sub-directory in the localization directory. The file name is the id of the node it provides localized text for. Files can be in either text (.txt) or markdown (.md) format. In case both text and markdown files are present, the markdown variant is preferred.
Tip
There are many Markdown editors that offer formatted preview of the text, or even allow editing of formatted text (like “normal” word processors.) Use your favorite search engine to find one - the list updated too often to include a recommendation here.
Useful CliRunner Commands¶
CliRunner offers the following commands for working with localizations:
\loc-create <localization name>- Creates a localization with the given name. The localization created uses data and texts from the model.
\loc-update- Updates all localizations, adding new nodes, sections, and policy space entities. It also lists which data can be removed from each localization (e.g. an answer that is not used anymore at the model).
\loc-diff <localization name>- Lists how the passed localization differs from the model. E.g., what nodes are not localized, what sections where localized but are not present anymore.